



In India, that moment is a trust breaker. Metro shoppers may tolerate it once. Beyond the metros, it feels like a bait-and-switch. And once trust drops, conversion follows.
Blog
How Can You Structure Your Content Beyond Keywords for AI Sourcing?
TL;DR
- Break pages into standalone semantic units. Each section should clearly answer one specific intent, without relying on the rest of the page.
- Write 40 to 120-word canonical answer blocks for key customer questions. Treat them as the single source of truth that AI models should extract from.
- Add structured metadata to each block, including intent labels, version IDs, timestamps, and ownership, so AI systems can verify accuracy and freshness.
- Control chunk size and content overlap. Keep core explanations between 100 and 300 words, and maintain logical continuity so that AI models can retain context.
- Attach evidence pointers to every major claim and centralise facts in a single authoritative location to prevent AI hallucinations and misrepresentation.
How do you measure AI visibility of a brand?
Content that used to rank at the top of Google search results is now often disappearing when an AI attempts to provide a grounded answer.
When your data is surfaced incorrectly, you lose more than just a click; you also lose buyer trust and sales velocity.
AI visibility is measured by how often and favourably a brand appears in AI-generated content. Key components include:
- Mention Visibility: Include the brand name in the answer.
- Citation Visibility: Content is used as a source (e.g., 'According to [Brand]...').
- Recommendation Visibility: A brand appears in 'best tools' or comparison lists.
- Representation Quality: The AI accurately describes a brand and its value proposition.
This blog breaks down a brand's AI visibility, how to structure content beyond keywords so your most important claims are picked, supported by evidence, and visible in AI responses.
What is the structure of a content block for AI extraction?
Size matters when an AI is trying to 'grip' your information. If a block is too small, the AI loses the context; if it's too big, the message gets buried in the noise.
- For deep concepts, aim for 100 to 300 words.
- For lists or 'how-to' steps, keep it tighteraround 40 to 120 words.
Always overlap your sections by about 20% so the AI doesn't lose the thread when moving from one block to the next.
How should you measure the quality of your content sourcing?
Here is a structured approach to measuring your content sourcing quality:
1. Qualitative Evaluation: The ‘Source Health’ Audit
Regularly audit your content to ensure it meets high standards in the following areas:
- Credibility & E-E-A-T: Assess if the information comes from reputable, expert sources (e.g., studies, government data, recognized industry experts).
- Check for author credentials and verified, non-anonymous, or non-AI-generated content.
- Accuracy & Fact-checking: Verify that facts, data points, and quotes are accurate, up-to-date, and properly cited.
- Relevance & Depth: Ensure the content thoroughly explores the topic rather than just providing a shallow summary.
- Originality: Ensure your content offers a unique perspective or original reporting, rather than taking content as it is from other sources without your own originality.
- Objectivity & Bias-check: Evaluate whether the information is unbiased or heavily slanted, which could damage trust in your brand.
2. Quantitative Metrics: Your Content Performance
Measure how the sourced content performs in terms of audience engagement and business impact.
Here are some of the engagement metrics that you can track:
- Average Engaged Time: Go beyond simple "time on page" to track "active" engagement (e.g., scroll depth, clicks, video watches).
- Scroll Depth: Measure how far down the page users read.
- Social Shares/Comments: Monitor how often your content is shared or discussed; this provides social proof.
Keep a check on these SEO & visibility metrics:
- Inbound Links: Monitor the number and authority (Domain Authority) of sites linking to your content.
- Rankings Movement: Track if your content improves in search engine results pages (SERPs).
Track these business impact metrics for your brand:
- Conversion Rates: Measure whether visitors who consumed the content took the desired action (e.g., signed up for a newsletter, downloaded a guide).
- Content ROI: Track if the content directly contributes to revenue or lead generation.
3. Process & Tools: Evaluation of the Content
- Use Tools for Assessment: Copyleaks for originality, Grammarly for quality, and Page Speed tools to ensure a good user experience.
- Implement a Rubric: Create a grading system (e.g., Pass/Fail or 1–5 scale) for evaluating content based on Accuracy, Tone, and Relevance.
- Peer Review: Have mentors or managers outside the content team who can provide an unbiased assessment.
Why is keyword-first thinking failing for conversational AI?
Keywords were built for a library system, but AI is a conversation system.
Modern sourcing pipelines don't just look for word matches; they look for relationships, timing, and the difference between a guess and a fact.
If your content relies solely on keywords, the AI might miss a perfect match because the context is too weak.
Even worse, the AI might pull a fragment of an answer that leads to a complete hallucination.
When different pages on your site conflict, the AI will likely pick the wrong source because it can't find a timestamp or a clear owner.
Comparing content types & sourcing challenges
Here is a table showing where common content types fail in AI sourcing and how to fix them.
.png)
Structuring content as semantic units and canonical answers
Stop designing content just for page rank and start designing it to extract your content.
Break content into semantic units. Think of these as ‘standalone ideas.’
A policy rule or a troubleshooting step should also make sense even if you strip away the rest of the page.
Create canonical answers. For every common question your customers ask, write a definitive 40-to-120-word ‘truth block.’
This is the preferred target for any AI trying to source a fact about your product.
An example to help you better understand this within your CMS with a heading, canonical answer, evidence pointer, and metadata.
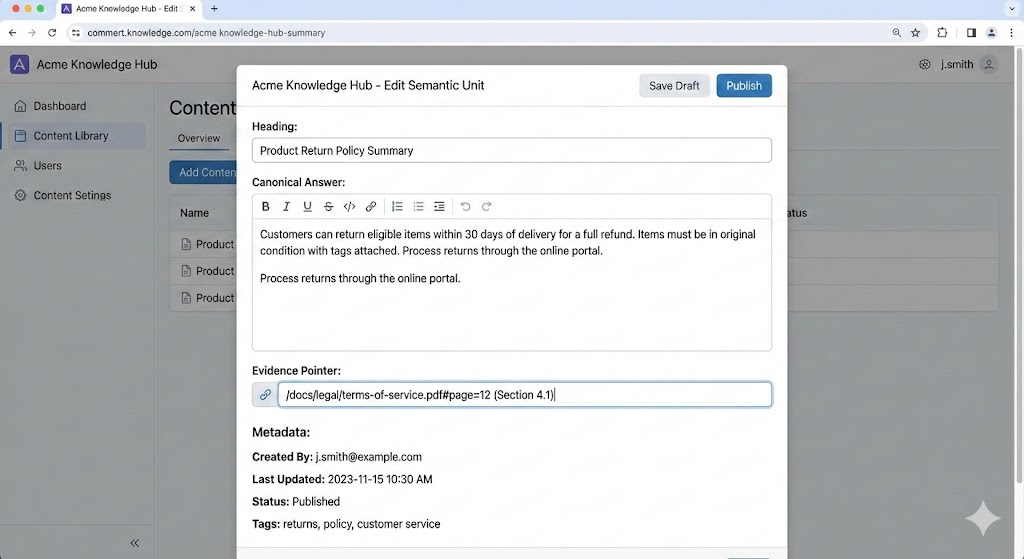
Start every unit with a heading that sounds like a real question a human would ask.
Always end with a source clause that tells the machine exactly when this was updated and who is responsible for it.
How do AI platforms use metadata to verify answers?
Metadata refers to structured signals like intent labels, version IDs, timestamps, and ownership that help AI systems verify and trust your content.
Metadata makes your content 'machine-friendly' and easy to audit.
Think of it as a digital passport for your data that proves its identity and location.
Every block of content should have a clear 'Intent Label' and a 'Trust Score' from your editorial team.
This allows the AI to boost your most reliable data and ignore outdated or low-confidence drafts.
Keep your tagging system small and strict. Authoritative IDs work much better than long, messy tags.
Build authority that AI can reliably cite
If you treat AI-ready content as a one-time cleanup, it will decay and fail within months.
As products change and policies update, your 'answer engine' will begin to lie to your customers if you donot update it from time to time.
When you enforce these AI visibility standards, your content stops being a static library and becomes vital business infrastructure.
Request an AI Search Visibility Audit
We review your priority pages and show exactly what to restructure for retrievability and trust.
Request an AI Search Visibility Audit
We review your priority pages and show exactly what to restructure for retrievability and trust.
Table of contents
Case Studies
About FTA
Keep Reading


Digital Marketing
February 12, 2026
How Large Language Models Rank and Reference Brands?
LLM model ranking matters here because AI systems pull from signals, pages, and proof points that feel reliable and easy to verify. Brands with clear positioning and credible evidence get repeated. Learn LLM model ranking, run a practical LLM comparison, and improve brand references.
Author Bio

I believe the best marketing shouldn't feel like marketing at all. In a world of digital noise, my work is driven by a simple goal: to create content that strikes the right chord with the people. At the end of the day, it's people (brands) engaging with people (consumers); so I write to invoke those human emotions.
My process is part storytelling, part nuanced writing. I blend the art of copywriting with the framework of campaign strategy and SEO, always starting with the 'who' and 'why' before the 'what'.
The result is a clear, authentic brand voice that builds community and drives growth. I'm also a passionate public speaker and a soft skills trainer, dedicated to bringing these ideas and stories to life for others, both on stage and on camera
Content Producer

