

TLDR
- AI search functions as a connector that performs parallel requests across the web to gather evidence rather than selecting a single top result.
- Roughly 85 % of web content is filtered out during AI preprocessing due to quality signals, technical mess, or duplication.
- Content must lead with meaning by answering the primary query within the first 50 to 70 words to survive the initial skimming phase.
- The confidence filter ignores retrieved content that introduces uncertainty or contradicts established evidence from other sources.
- Effective optimization requires providing atomic facts at a grade 3-5 reading level to reduce the machine's inference cost.
- AI visibility has shifted from a ranking problem to a survival problem, in which content must pass through multiple technical and confidence filters to be cited.
How does AI content chunking impact search visibility?
The shift from traditional search engine optimization to the era of artificial intelligence has fundamentally changed how information is discovered. In the past, we focused on keyword density and backlinks to rank on a page of blue links.
Today, AI models act as connectors/coordinators, dispatching dozens of parallel requests across the web to answer a single user query.
This change means that visibility is no longer about being number one for a specific keyword but about appearing across the entire set of fanned-out results the orchestrator pulls.
In this new landscape, your content is broken down into segments known as chunks.
Each chunk must stand on its own as a reliable piece of information.
The goal for any modern business is to reduce the retrieval cost per unit of truth.
This involves structuring data into atomic facts with explicit context so that the machine can confidently name your brand as the source.
If your information is buried under fluff or lacks a clear structure, the AI will likely skip it in favour of a competitor whose content is easier to parse and verify.
What are the stages of AI content retrieval?
When an AI system looks for an answer, it does not simply read every page it finds.
Instead, it moves through a multi-stage evaluation process to determine which content is worth the computational power required for analysis.
This process begins with metadata and progresses to intensive parsing as the model gains confidence in the page's relevance.
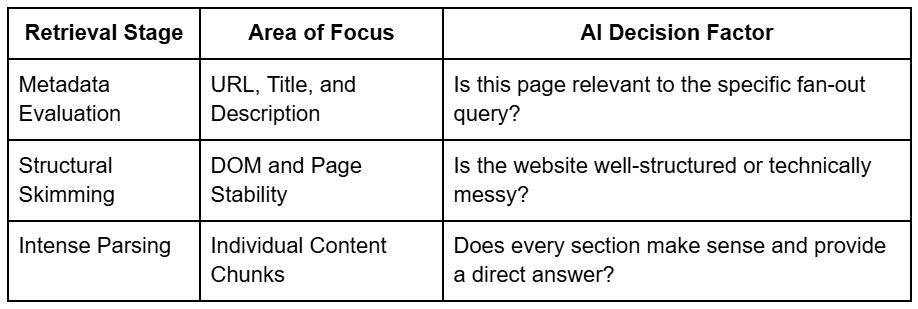
The first gate is the most critical because if your meta title or description is irrelevant to the specific sub-query the AI is running, your page is discarded before it is even opened.
Many creators leave metadata blank, but in the AI era, it is better to hardcode descriptions that explain exactly what the page covers to help the model pass the first stage.
Once a page passes the initial filters, the model performs a light skimming to assess the site's stability and structure before committing to a full analysis of each chunk.
Why is my website content ignored by AI models?
It is a sobering reality that AI models ignore about 85% of web content during preprocessing. This is not always a reflection of the quality of the ideas but rather a result of technical and structural issues that trigger exclusion filters.
Reports on models like GPT-4 show that up to 70% of scraped web content is filtered out due to quality signals, duplication, and formatting issues.
Common patterns that lead to exclusion include thin or duplicate content. Pages with fewer than 300 words or those that are more than 80% similar to existing content are often removed automatically during deduplication.
Technical barriers are another major hurdle. Content behind paywalls or requiring authentication is invisible to training datasets, creating a paradox where your most premium information has the lowest visibility.
Additionally, AI models heavily favour recent information. Content without clear publication dates or with timestamps older than five years experiences an 80% reduction in inclusion rates.
How does the AI confidence filter work?
Even if your content is successfully retrieved, it may not appear in the final answer because it must first survive a confidence filter.
The primary goal of an AI assistant is to generate a response that is reliable and safe for the user.
If a retrieved chunk introduces uncertainty or contradicts evidence found in other trusted sources, the model will likely ignore it.
This is particularly true for subjective or controversial topics, where the model is seeking consensus.
The chances of being featured decrease significantly if your answer is an extreme outlier or lacks enough supporting context to be verified. This is why consistency across different digital surfaces is vital.
When multiple websites explain a concept in similar ways, they reinforce each other and increase the model's confidence in that information.
This phenomenon is known as a fusion reward, where the most consistent and retrievable truth is chosen for the final response.
To pass this filter, you must back up your claims with relevant sources and industry expertise to build the necessary trust.
How to make content AI-friendly for search engines?
In the fast-paced environment of AI retrieval, you must lead with the meaning of your content immediately.
To pass the second stage of the retrieval process, you need to answer the potential query within the first 50 to 70 words of a section.
If the model does not find a clear and relevant answer during its light-skimming phase, the page is discarded before the intensive parsing stage begins.
This rule requires a shift away from traditional storytelling that builds up to a point. Instead, you should adopt a direct approach that mirrors the way users interact with AI assistants.
Providing the most critical information upfront reduces the model's compute cost and makes it easier for the system to validate whether your page is worth further analysis.
This level of clarity is not just for the AI; it also helps human users seeking quick, accurate answers to their questions.
How to Make Your Content Work for ChatGPT and AI Answers?
Here are the five ways to make your content usable for ChatGPT and AI answers:
- Lead with the answer, not the build-up
Start every section by directly answering the core query. AI skims first and decides quickly whether your content is useful. - Use simple, low-effort language
Write at a basic reading level so meaning is instantly clear. Complex phrasing increases the chances of being ignored. - Break content into atomic ideas
Keep sentences short and focused on one idea. This helps AI extract and reuse your content without confusion. - Structure content like real questions and answers
Use Q&A format and include FAQs. This aligns with how users ask and how AI retrieves information. - Remove ambiguity and define context clearly
Use clear headings and structured data where possible. AI prefers content that does not require interpretation.
Clear, structured, and easy-to-process content is what AI uses.
Why most content will not survive AI search?
AI visibility is no longer about ranking. It is about passing three gates: retrieval, confidence, and fusion. Your content must be technically clean to be retrieved, factually consistent to be trusted, and simple enough to be directly used in final AI answers.
Most content fails before it even reaches the final stage. Teams that audit for these gaps and structure content for machine consumption will build a clear advantage while others remain invisible.

Do you want more traffic?

How To Use Chunking In AI To Improve Rag Accuracy And Lower Costs?

